
By Guillaume Matheron, corrections by Alexander Belikov
IT systems are like onions, they have layers. And when the bottom-most layer fails, everything follows. This is the story of our experience with WD Red hard disk drives at Hello Watt, and how even while following good practices of system administration, deceptive advertising can cause your business to lose weeks of work.
Our data pipeline
Even at a company like ours where everything important happens in the cloud, storing and accessing large amounts of data in-house makes sense given the cost of cloud storage and the relatively low price of HDDs.
The main data-driven aspect of Hello Watt activity is the analysis of the data of our customers’ smart electricity meters. The analysis is implemented in our B2C product called Coach Conso, which is able to partially disaggregate the load curve into different appliances such as heating, water heating and others. A team of three permanent employees develops models that analyze this data, and these models are then used in production.
Therefore, the main type of data we handle is that of time series: one for each smart meter, with a time resolution of thirty minutes. When a model is used in production, the data is fetched from a production environment, we use MongoDB Atlas, a commercial service. However, for model development and experimentation is done locally and to alleviate bandwidth costs, we have a local anonymized replica of customer data on an in-house server.
First indications of a problem
A few months ago, we wanted to expand to a new server, and to keep things flexible settled on proxmox with a ZFS filesystem for easy snapshots, backups and N+2 HDD redundancy.
We bought WD Red HDDs since they were advertised for NAS use, without realizing that this type of disk has been becoming more and more controversial in the context of NAS usage. Even at the time writing [September 2021], searching for “WD Red NAS” on Google yields only commercial offer links on the first page, while the first alarming post is on the second page. Even the first alarming links vaguely warn you about decreased write performance. However, as we would experience, the damage could be much worse than simply lower speeds.
For the first couple of months everything went well. Without a clue about the issues of these disks, we set up ZFS, then proxmox, then started setting up a few VMs and moving our local databases there. We had backups, but since we were still waiting on a second proxmox NAS, the backups were stored on the same ZFS pool. This was a precaution against bad admin commands on the VMs, and not against hardware failures of course. Although with N+2 HDD redundancy we were feeling pretty confident about our chances unless there was a fire. It didn’t really matter anyway because all the databases were mirrored from prod, and although setting up the VMs had taken about a week, nothing was irreplaceable.
After two months the first error appeared.
root@apollo:/# zpool status -v pool: rpool state: DEGRADED config:NAME STATE READ WRITE CKSUM
rpool DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
ata-WDC_WD40EFAX-***-part3 DEGRADED 0 0 0
ata-WDC_WD40EFAX-***-part3 DEGRADED 0 0 0
ata-WDC_WD40EFAX-***-part3 DEGRADED 0 0 0
ata-WDC_WD40EFAX-***-part3 FAULTED 0 16 0 too many errors
logs
nvme0n1 ONLINE 0 0 0
cache
nvme1n1 ONLINE 0 0 0
The status report above reveals that 16 write failures had occurred on the fourth drive of the array, causing the disk to transition to FAULTED with an error message too many errors, and the overall state of the pool to become DEGRADED.
To analyze what is going on here, it is important to understand how ZFS handles a RAIDZ2 pool. The four disks present N+2 redundancy, meaning that any two disks can fail without the data being affected. Therefore, although we have four 4 TB drives, only 2 TB are in usage. This kind of redundancy cannot be obtained by simply mirroring the drives, because it must survive the failure of any two drives. Therefore, ZFS uses mathematical tricks in the form of error correcting codes to spread the data evenly throughout the four disks. An added benefit is that read operations are in theory a bit faster on RAIDZ2 because the data can be read from several disks at once.
Troubleshooting hell
In parallel, we identified these worrying lines in the syslog :
[ 3007.480648] ata8.00: exception Emask 0x0 SAct 0x1ecc0 SErr 0x0 action 0x0
[ 3007.480804] ata8.00: irq_stat 0x40000008
[ 3007.481250] ata8.00: failed command: WRITE FPDMA QUEUED
[ 3007.481783] ata8.00: cmd 61/08:30:90:38:81/00:00:b1:00:00/40 tag 6 ncq dma 4096 out
res 41/10:00:90:38:81/00:00:b1:00:00/00 Emask 0x481 (invalid argument) <F>
[ 3007.482891] ata8.00: status: { DRDY ERR }
[ 3007.483421] ata8.00: error: { IDNF }
[ 3007.484934] ata8.00: configured for UDMA/133
[ 3007.484941] sd 7:0:0:0: [sdc] tag#6 FAILED Result: hostbyte=DID_OK driverbyte=DRIVER_SENSE cmd_age=8s
[ 3007.484943] sd 7:0:0:0: [sdc] tag#6 Sense Key : Illegal Request [current]
[ 3007.484945] sd 7:0:0:0: [sdc] tag#6 Add. Sense: Logical block address out of range
[ 3007.484946] sd 7:0:0:0: [sdc] tag#6 CDB: Write(16) 8a 00 00 00 00 00 b1 81 38 90 00 00 00 08 00 00
[ 3007.484947] blk_update_request: I/O error, dev sdc, sector 2978035856 op 0x1:(WRITE) flags 0x700 phys_seg 1 prio class 0
[ 3007.485108] zio pool=rpool vdev=/dev/disk/by-id/ata-WDC_WD40EFAX-68JH4N1_WD-WX92DA09S9XH-part1 error=5 type=2 offset=1524753309696 size=4096 flags=1808aa
[ 3007.485117] ata8: EH complete
This directed us straight to a hard disk issue, and we immediately thought of replacement of a faulty drive, of course, after wiping it clean using ATA Secure Erase.
A couple of days later, a new error sent us straight into damage-control mode:
root@apollo:/# zpool status -v
pool: rpool
state: DEGRADED
config:NAME STATE READ WRITE CKSUM
rpool DEGRADED 0 0 0
raidz2-0 DEGRADED 0 0 0
ata-WDC_WD40EFAX-***-part3 DEGRADED 0 0 0
ata-WDC_WD40EFAX-***-part3 DEGRADED 0 0 0
ata-WDC_WD40EFAX-***-part3 FAULTED 0 16 0 too many errors
******************** UNAVAIL 0 0 0 was /dev/disk/by-id/ata-WDC_WD40EFAX-***-part3
logs
nvme0n1 ONLINE 0 0 0
cache
nvme1n1 ONLINE 0 0 0
A second disk had failed… The likelihood of two disks failing at the same time is extremely low, so we turned our head to other hardware failures such as our backplate, SATA cables, power supply, and even motherboard.
After lengthy investigations we came back to the drives and found several descriptions of our issue online. Most of the criticism of WD’s SMR technology in NAS drives was centered around write performance, but an article reported the exact issue we had, with drives being excluded from the ZFS RAID because of write timeouts.
In the meantime all our drives started having errors and some files were corrupted.
The problem with SMR
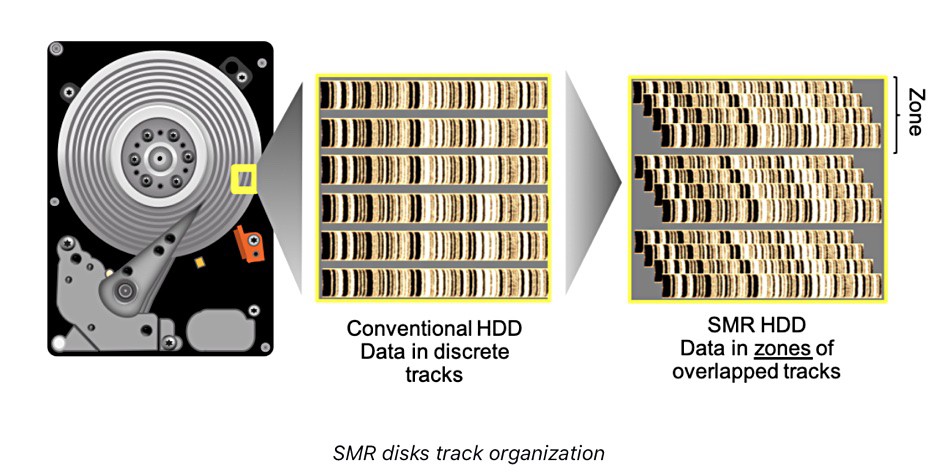
SMR, or Shingled Magnetic Recording is a technology that allows denser packing of data on a spinning disk, therefore reducing cost of storage. It takes advantage of the fact that read heads can be made smaller than write heads to partially overwrite existing tracks in a way that the adjacent track can still be read by the smaller read head.
This contrasts with Conventional Magnetic Recording (CMR), where each write track is completely separated from the others.
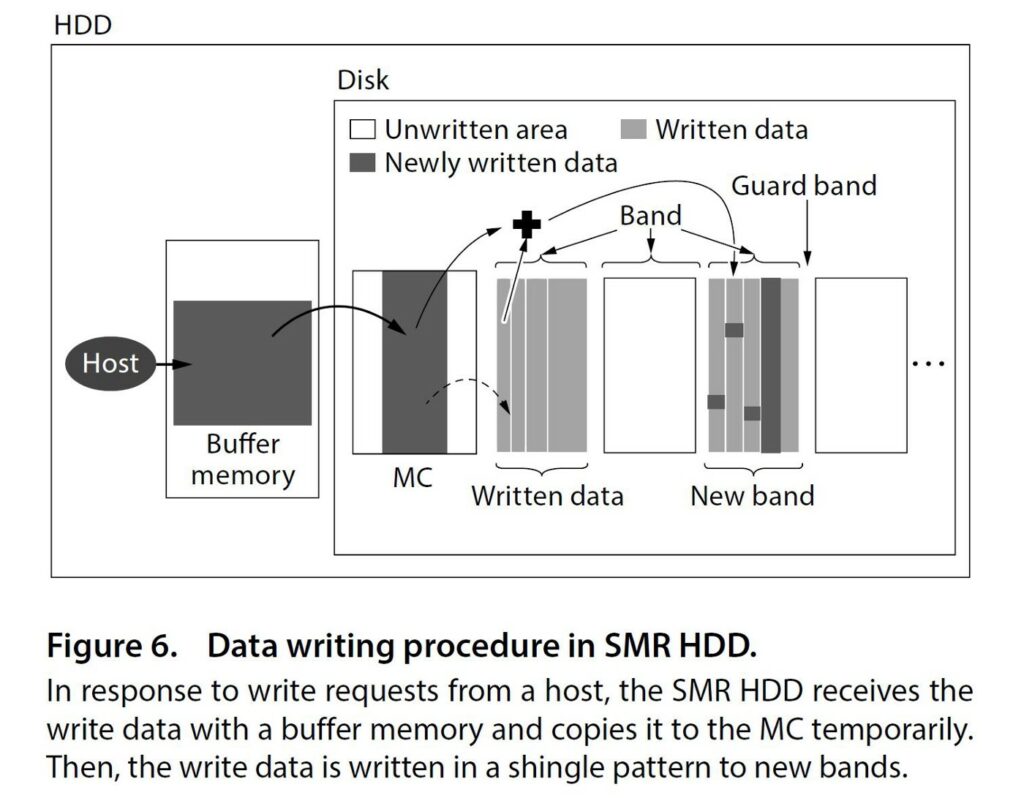
Unfortunately, SMR means there is no way to overwrite data in-place without also overwriting the adjacent read track. The solution to this is to first read the adjacent track, then overwrite the data, then overwrite the adjacent track, re-creating the shingles.
Of course, re-writing the adjacent track means destroying the data from the next track and so on. In practice, SMR tracks are grouped into zones, that are separated by guard tracks. Any change to data in a zone requires reading and overwriting the entire zone, which has a large impact on write performance.
To mitigate this issue, drive manufacturers use a Media Cache (MC) which is an area of the disk that uses CMR. Write intentions are written to the media cache until the disk is idle, then it starts to copy this data to shingled zones, freeing up the MC to accommodate new writes.
However, during sustained writing sessions as expected in a server environment, as the empty space in MC decreases, the write speed slows down to a crawl. In our case the WD Red drives even hung for several minutes, causing the SATA driver to throw write errors, ultimately causing the ZFS software to reject the drive as faulty.
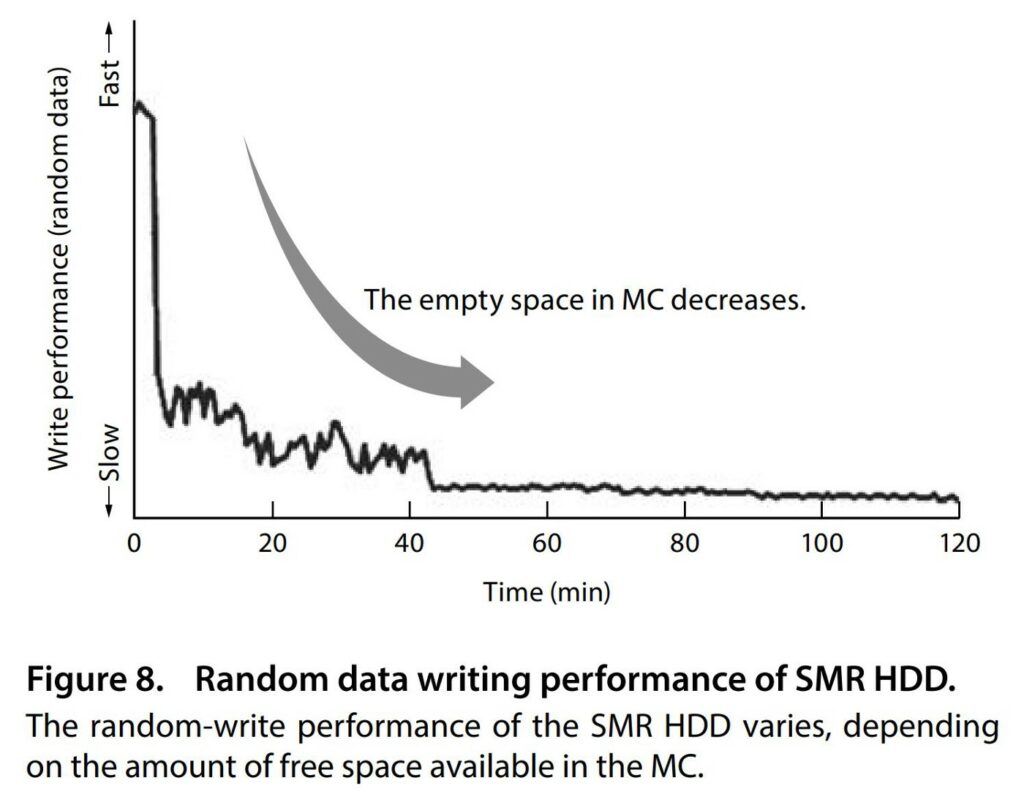
This is especially problematic since sustained writing is certainly expected in a RAID setup where changing a disk requires writing all the parity data in one stretch that can last hours to days.
Conclusion
SMR drives have design constraints that make sustained write performance abysmal, with occasional freezes that can cause a drive to be considered defective and be excluded from a RAID setup, cascading into a major outage.
Some of these issues could potentially be mitigated with smarter software both on the drive and driver sides, but for now it seems the only safe bet is to stick with CMR drives for NAS and any kind of redundant RAID configuration.
Sources
- https://blocksandfiles.com/2020/04/15/shingled-drives-have-non-shingled-zones-for-caching-writes/
- https://blocksandfiles.com/2020/04/23/western-digital-blog-wd-red-nas-smr-drives-overuse/
- https://www.cachem.fr/disque-dur-smr-pmr-crm/
- https://news.knowledia.com/US/en/articles/wd-red-smr-vs-cmr-tested-avoid-red-smr-75c2bbbf1b8754f33e6b70486ff6ee9aca884b3a