-
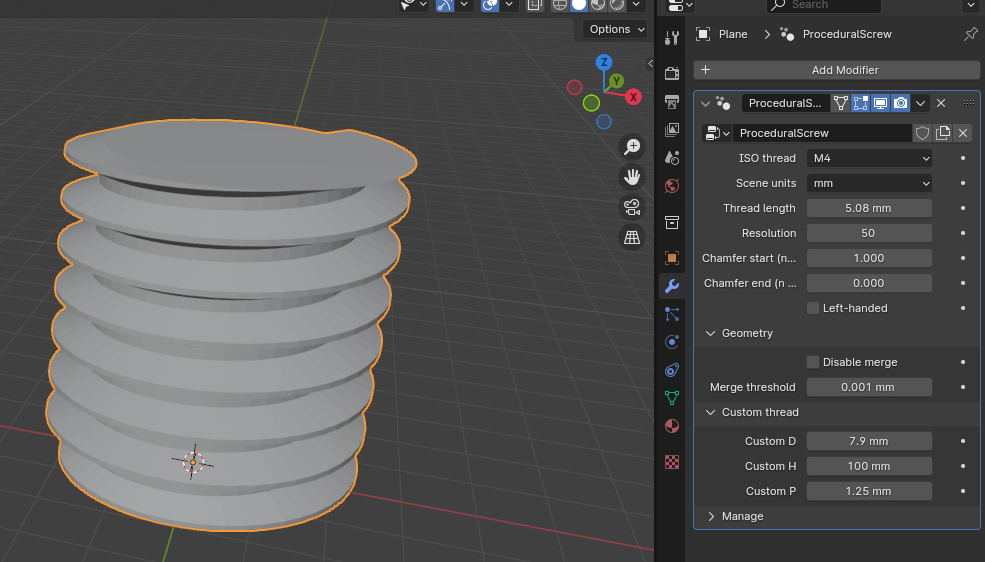
Procedural threads in Blender with geometry nodes
I love designing functional models for 3D printing with Blender. I know it’s not a common choice and CAD software is usually preferred, and I have tested many but none has offered me the flexibility and speed of Blender for my projects. One issue that I always had was generating screws, bolts and threads. Of…
-
Change ZFS volblock on a running Proxmox VM
When we set up our infrastructure initially (Ubuntu VMs on proxmox with ZFS storage), I used the default block size, which was 8kB at the time.. Space considerations when using zvols on RAIDz Smaller block sizes are good because they limit write amplification (writing one byte in the guest require writing a full block to…
-
IP-based geolocation in Clickhouse with IPv6
While setting up my analytics with clickhouse, I tried to map IPs to countries. I found this article that perfectly explains how to do this with IPv4, but gives no indication of how to adapt the queries to ipv6. The beginning of the process is identical: fetch IP ranges from dbip-city-ipv6 using a table with…
-
Reinstall proxmox while keeping all the configuration and VMs intact
-
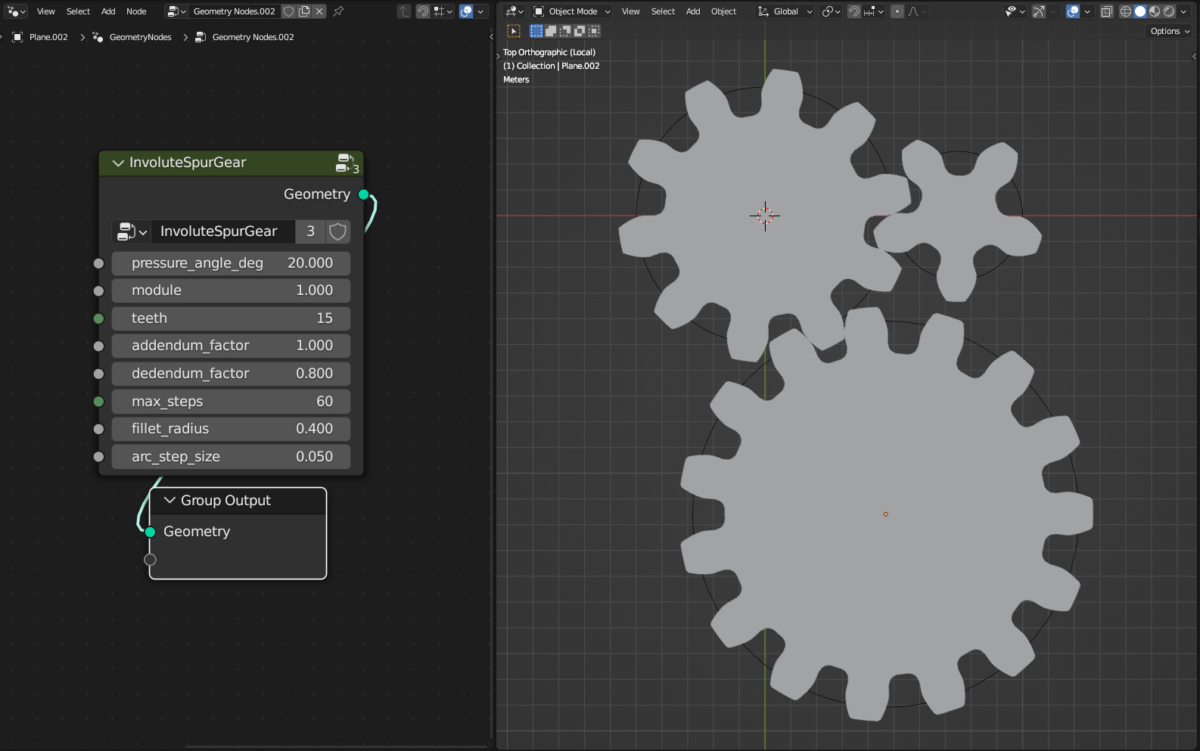
Procedural involute spur gears in Blender 3 with geometry nodes
I love designing functional models for 3D printing with Blender. I know it’s not a common choice and CAD software is usually preferred, and I have tested many but none has offered me the flexibility and speed of Blender for my projects. One issue that I always had was generating gears and bolts. Of course…
-
Taking advantage of ZFS for smarter Proxmox backups
Let’s say we have a Proxmox cluster running ~30 VMs using ZFS as a storage backend. We want to backup each VM hourly to a remote server, and then replicate these backups to an offsite server. Proxmox Backup Server is nicely integrated into PVE’s web GUI, and can work with ZFS volumes. However, PBS is…
-
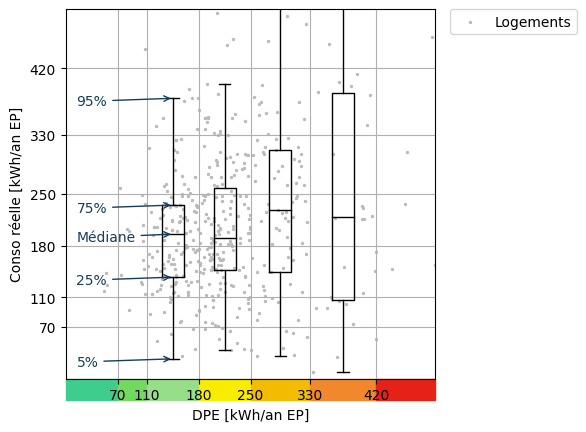
Comparer DPE et consommation a-t-il un sens ?
Récapitulatif des publications à ce sujet : Hello Watt a publié le 4 janvier une étude concluant à un manque de corrélation entre le DPE d’un logement, censé évaluer sa performance énergétique, et sa consommation d’énergie mesurée par les compteurs communicants. Pourquoi cette étude ? Dans sa mission de favoriser la transition énergétique des ménages,…
-
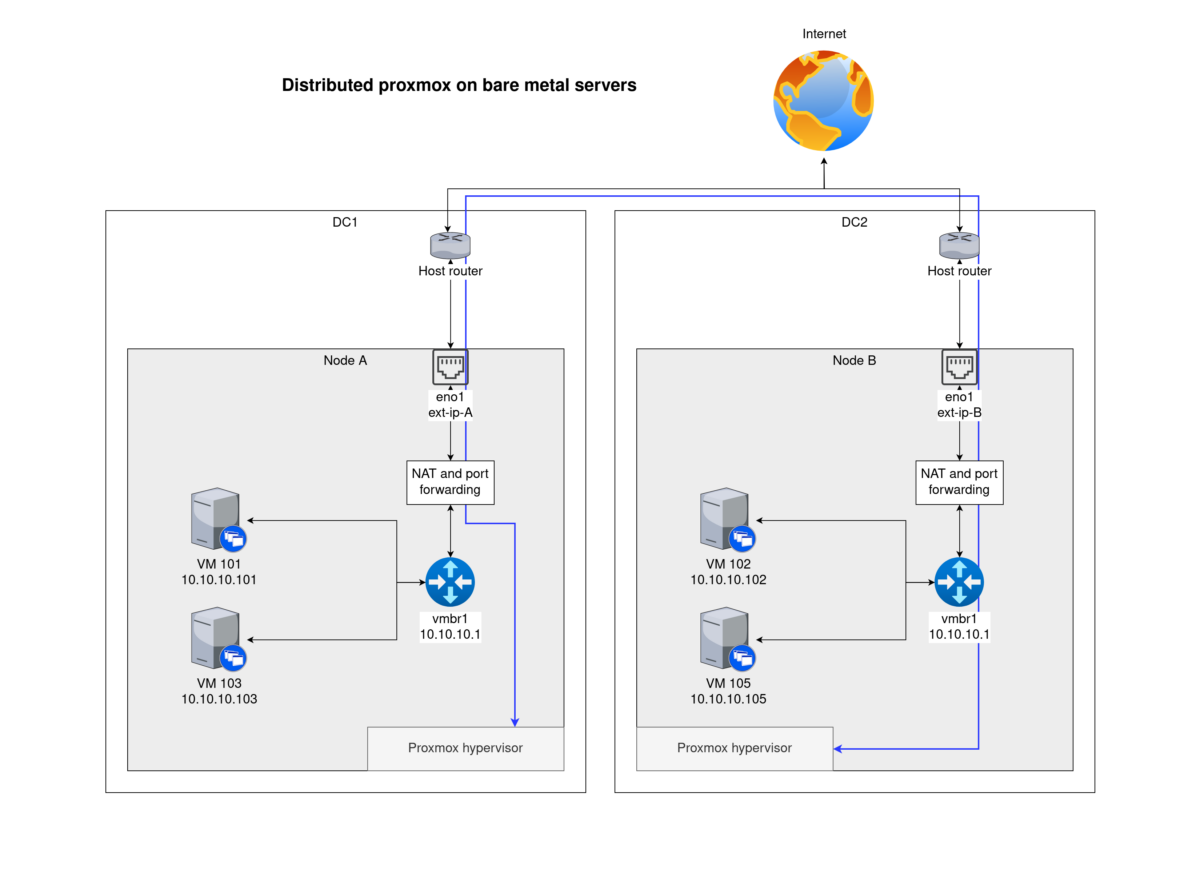
Proxmox cluster on distant bare metal servers
I run a Proxmox cluster with three nodes that are set up on three rented bare-metal servers from OVH in different datacenters. This is a pretty unusual setup, because bare-metal rental companies to not allow bridging on their network interface. Bridging in a typical racked cluster In this context, bridging means that a single physical…
-
Predicting Home Energy Consumption, the Data-Driven Way
At Hello Watt, we help residential energy consumers reduce their energy bills through various means. This involves estimating their electricity and gas consumption based on information we collect either over the phone or through a form. We developed Consumption Calculator, a new model that works very similarly to the previous model except its coefficients are…
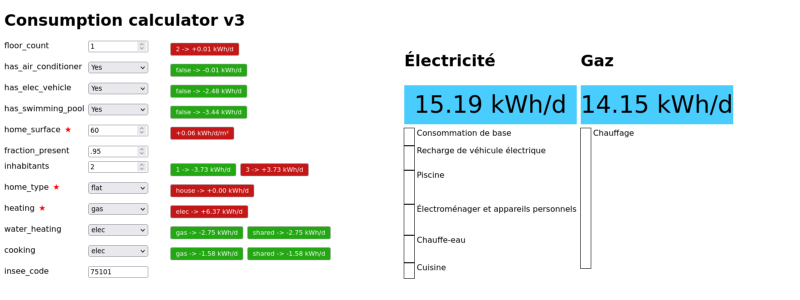
-
Domain Knowledge Aids in Signal Disaggregation; the Example of the Cumulative Water Heater
In this article we present an unsupervised low-frequency method aimed at detecting and disaggregating the power used by Cumulative Water Heaters (CWH) in residential homes. Our model circumvents the inherent difficulty of unsupervised signal disaggregation by using both the shape of a power spike and its temporal pattern to identify the contribution of CWH reliably.…
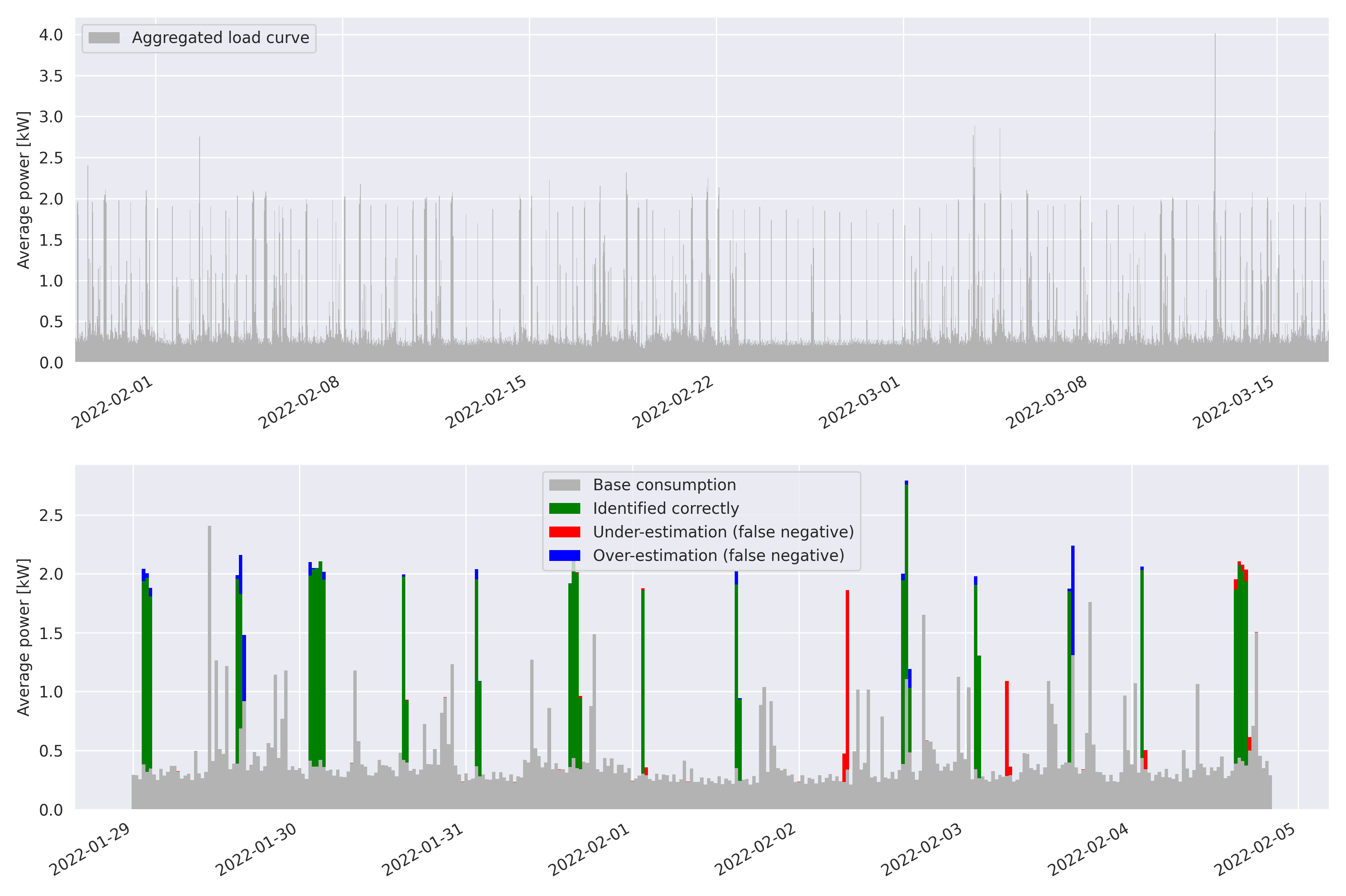

Guillaume Matheron
Data scientist, PhD in computer science