
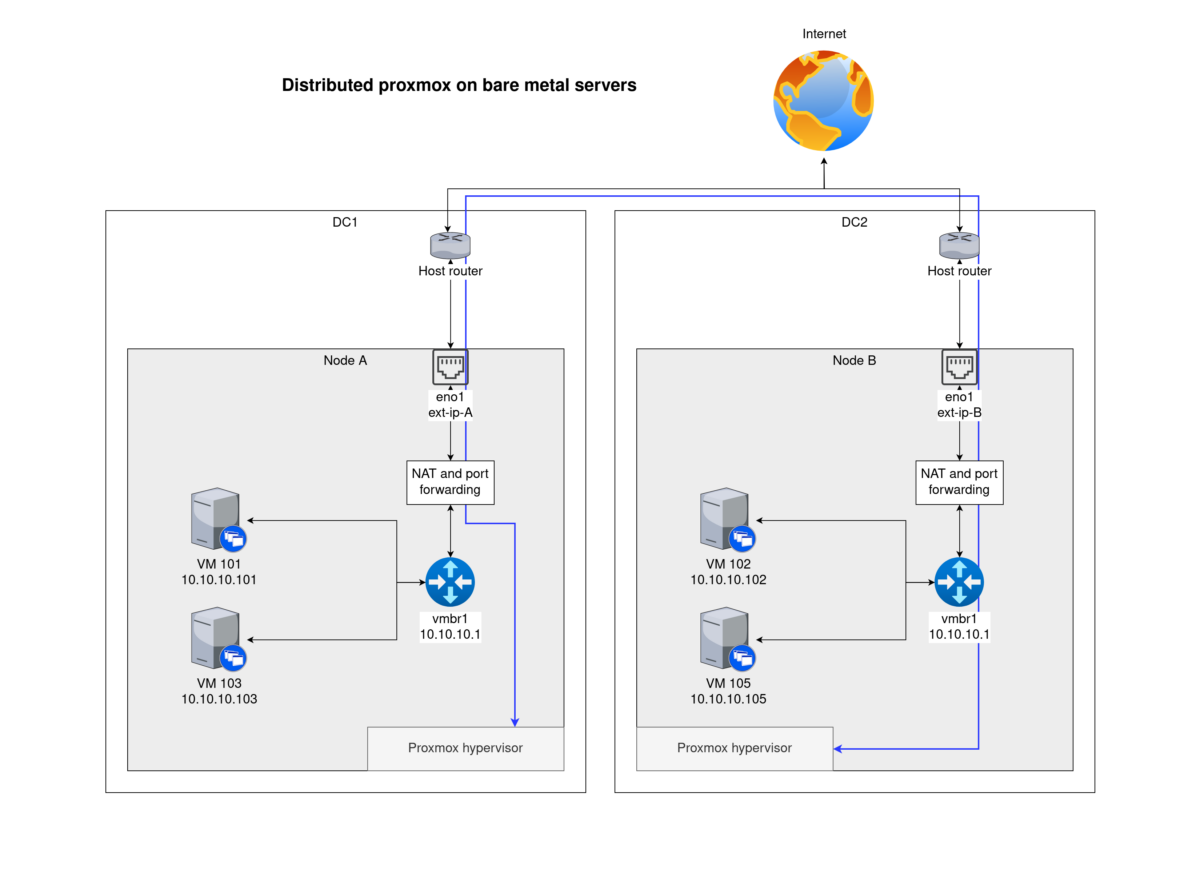
I run a Proxmox cluster with three nodes that are set up on three rented bare-metal servers from OVH in different datacenters. This is a pretty unusual setup, because bare-metal rental companies to not allow bridging on their network interface.
Bridging in a typical racked cluster
In this context, bridging means that a single physical network interface card (NIC) will act as a L2 switch and will transmit and respond to packets with several MAC addresses that will then be internally routed to the appropriate VMs. When the server is connected to a router and a DHCP server for instance, this allows each VM to request its own private IPv4 address from the DHCP server transparently, and communicate through a NAT on the router.
This is especially convenient for a virtualization cluster where all nodes are connected to the same router, because moving a VM from one node to the other is akin to moving a physical machine from one port of a router to the other: it does not require the VM to change IP address, any port forwarding rules in place are preserved, and this can usually be performed without even shutting down the VM. This allows for high availability (HA) if the storage backend is itself HA, or at least easy node maintenance.
Distributed cluster with a single public IP per node
However, with a rented bare-metal server, the server is only allowed to use a single predefined IP and MAC address (usually a public IP and the MAC of its NIC), so bridging the physical is not an option. The solution then is to setup a virtual interface acting as a L2 switch, with the node acting as a L3 gateway between the internal node network (with private IPs such as 10.10.10.123) and the internet. VMs can communicate with each other using these private IPs, but all external connections go through an IPv4 NAT and appear to originate from the single public IPv4 allocated to the server.
Dealing with several VMs on a single IP
Now we have several VMs that share the same IP, and a node acting as a router and performing L3 NAT so that each VM can connect to outside services.
For incoming connections, the node can perform port forwarding to different VMs, as you would configure on a home router. However each outside port can only be forwarded to a single VM. Some protocols allow for some kind of multiplexing, others need different solutions.
HTTP(s) with SNI
Multiplexing HTTP is often easy based on the value of the Host header. Plain HTTP requests can simply be intercepted and forwarded, with a technique called Reverse Proxying.
HTTPs requests usually cannot be inspected, but a loophole in the protocol actually permits reverse proxying in the same way as for unencrypted traffic. The Server Name Identification (SNI) extension of the TLS protocol contains a plain-text copy of the Host header. This is designed to avoid a chicken-and-egg problem in certificate verification: without SNI a server hosting multiple websites wouldn’t know which certificate to use when initiating a connection, which happens before the Host header is sent.
In a sense using SNI for reverse proxying is close to the intended usage, since in both cases a single IP is serving different websites. It’s just that with reverse proxying the Host header is used to figure out which VM to forward the traffic to, and on the server itself it is used to select the certificate (or virtual host in apache terminology).
VM migrations in a distributed cluster
Depending on the services hosted on the VMs, this can make migrations much harder because the public IP of a VM is determined by the node that hosts it. Some services such as gitlab runners don’t require a fixed IP, and in some cases it may be possible to make the service IP-agnostic by accessing it through a VPN such as wireguard. But for services such as mail or web servers, the only option is to update the DNS records dynamically when the VM changes node, and use a low enough TTL to limit the downtime during migrations.
This makes high availability tricky: the DNS propagation time gets added to the failover delay. When self-hosting the DNS server, high availability is even more tricky.
High availability for a DNS VM
Migrating a DNS server presents an additional challenge: changing the DNS records of the parent zone usually presents a much higher propagation time.
Luckily, DNS is made to be redundant, so in theory there is no need to migrate a DNS server when it goes down, since all DNS clients will simply shift to using other secondaries of the zone.
However when the master DNS server is on the same cluster as other VMs that rely on it, in a HA scenario these VMs need to contact the master DNS server (which just went down) to update their record.
One approach is to automatically migrate the master DNS server to another node, and have VMs try both possible IPs when updating their zone. This was a major pain to configure so we used a simpler approach.
We put the DNS master VM on a dedicated (third) node, with no automatic migrations. If this third node goes down, no zone updates are permitted, but all services are still running. In another node goes down, the master DNS VM is still up and can handle zone updates.