-
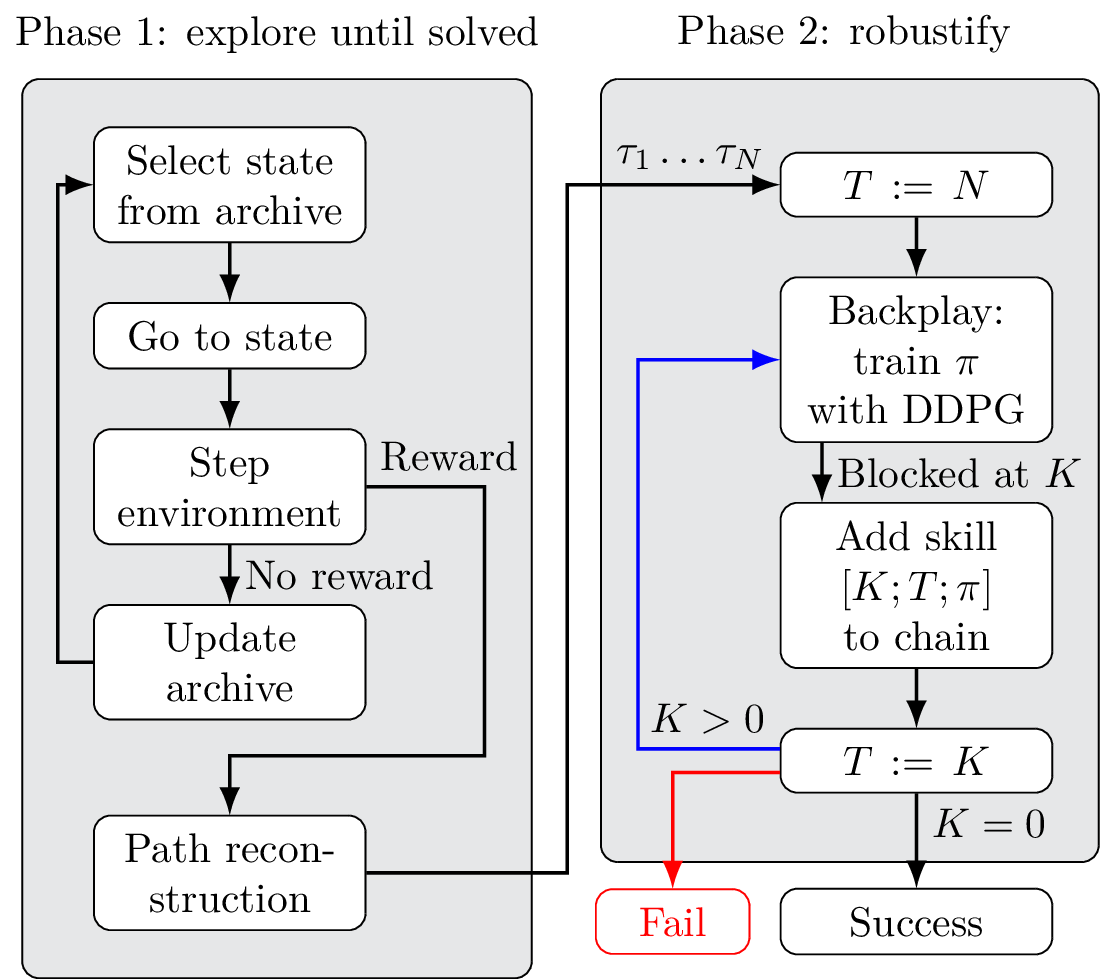
PBCS: Efficient Exploration and Exploitation Using a Synergy between Reinforcement Learning and Motion Planning
The exploration-exploitation trade-off is at the heart of reinforcement learning (RL). However, most continuous control benchmarks used in recent RL research only require local exploration. This led to the development of algorithms that have basic exploration capabilities, and behave poorly in benchmarks that require more versatile exploration. For instance, as demonstrated in our empirical study,…
-
The problem with DDPG: understanding failures in deterministic environments with sparse rewards
In environments with continuous state and action spaces, state-of-the-art actor-critic reinforcement learning algorithms can solve very complex problems, yet can also fail in environments that seem trivial, but the reason for such failures is still poorly understood. In this paper, we contribute a formal explanation of these failures in the particular case of sparse reward…

Guillaume Matheron
Data scientist, PhD in computer science