Hello everyone !
My name is Guillaume Matheron and I am a data scientist at Hello Watt. I use this website as both my CV and portfolio, and occasionally write a few technical posts about things I find interesting such as computer science, programming, networking and security.
Work
 Hello Watt
Hello Watt
Data Scientist
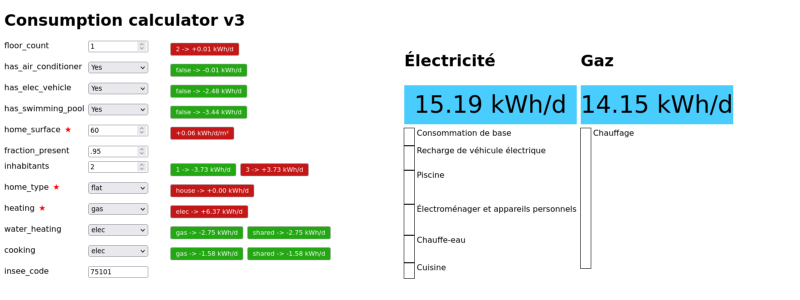
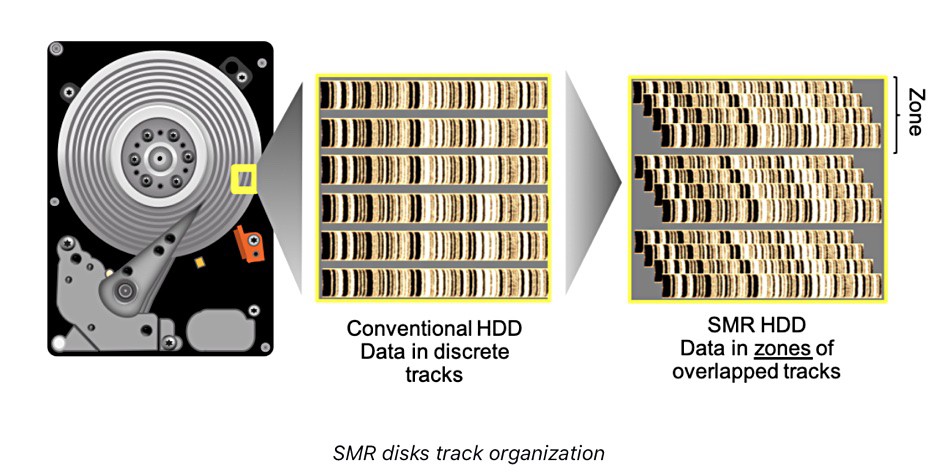
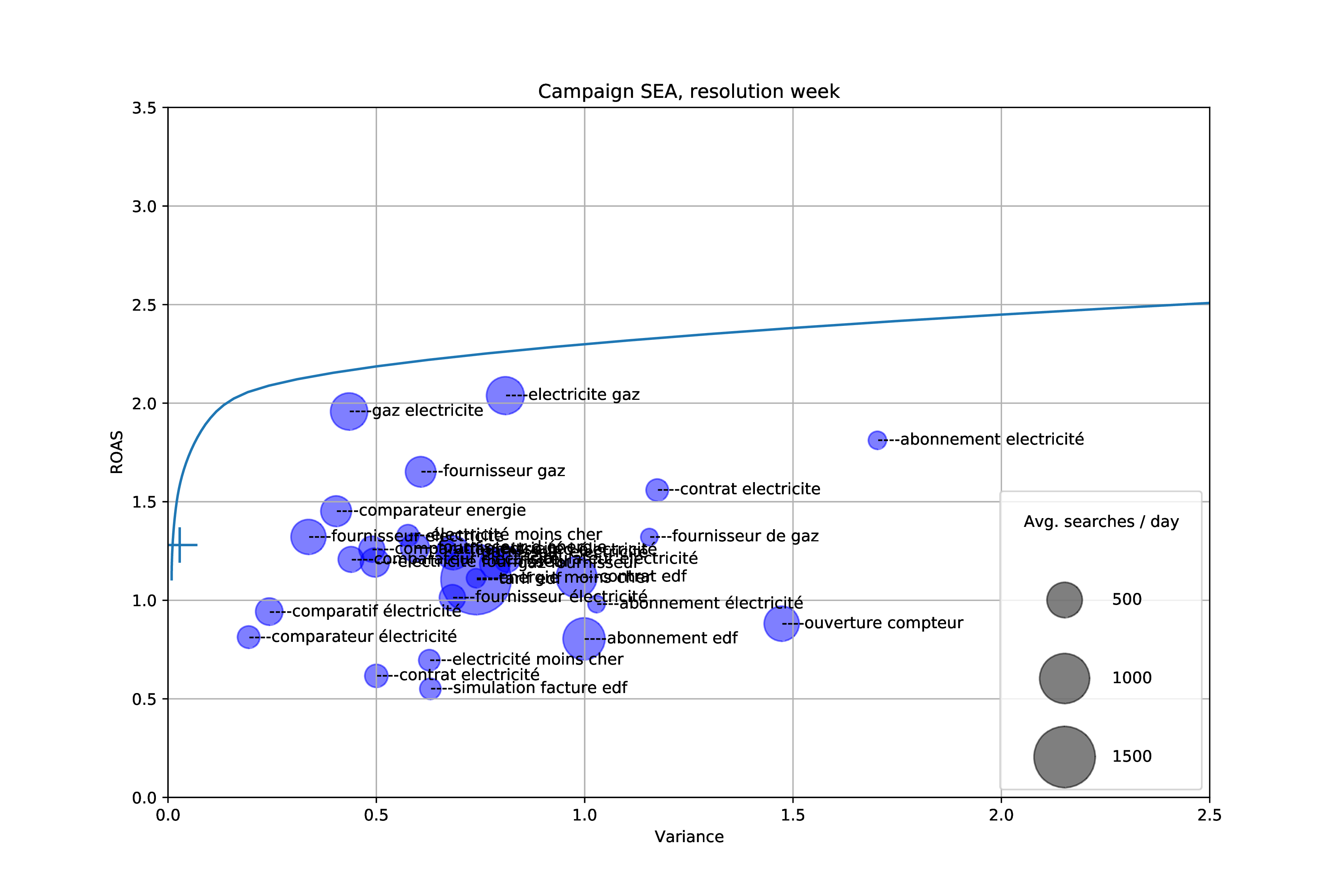
I mostly design and implement algorithms for Non-Invasive Load Monitoring (python, pandas, pytorch, pyro), but I also do software engineering, network engineering (Mikrotik routers, wifi, radius, OpenVPN, wireguard), monitoring (Grafana, Prometheus), application security and infrastructure (Proxmox, building our own servers, etc.).
 NASA Jet Propulsion Laboratory
NASA Jet Propulsion Laboratory
Software technologist (intern, 2016)
Designing the path planning software of Perseverance (Mars2020 rover)
Education
 PhD in machine learning
PhD in machine learning
Institut des Systèmes Intelligents et de Robotique (2017-2020)
Integrating motion planning and reinforcement learning to solve hard exploration problems.
 Master in Computer Science – ENS Paris
Master in Computer Science – ENS Paris
Admitted in 2014 through the competitive exam in computer science (6th place).
MS in computer science: MPRI (Parisian Master of Research in Computer Science).
 Lycée privé Sainte-Geneviève
Lycée privé Sainte-Geneviève
CPGE MPSI / MP*
Mathematics, physics, chemistry, computer science.
 Lycée International de Valbonne
Lycée International de Valbonne
Baccalauréat option internationale in American litterature (18.3/20)
Mention at the concours général in physics.
Peer-reviewed publications
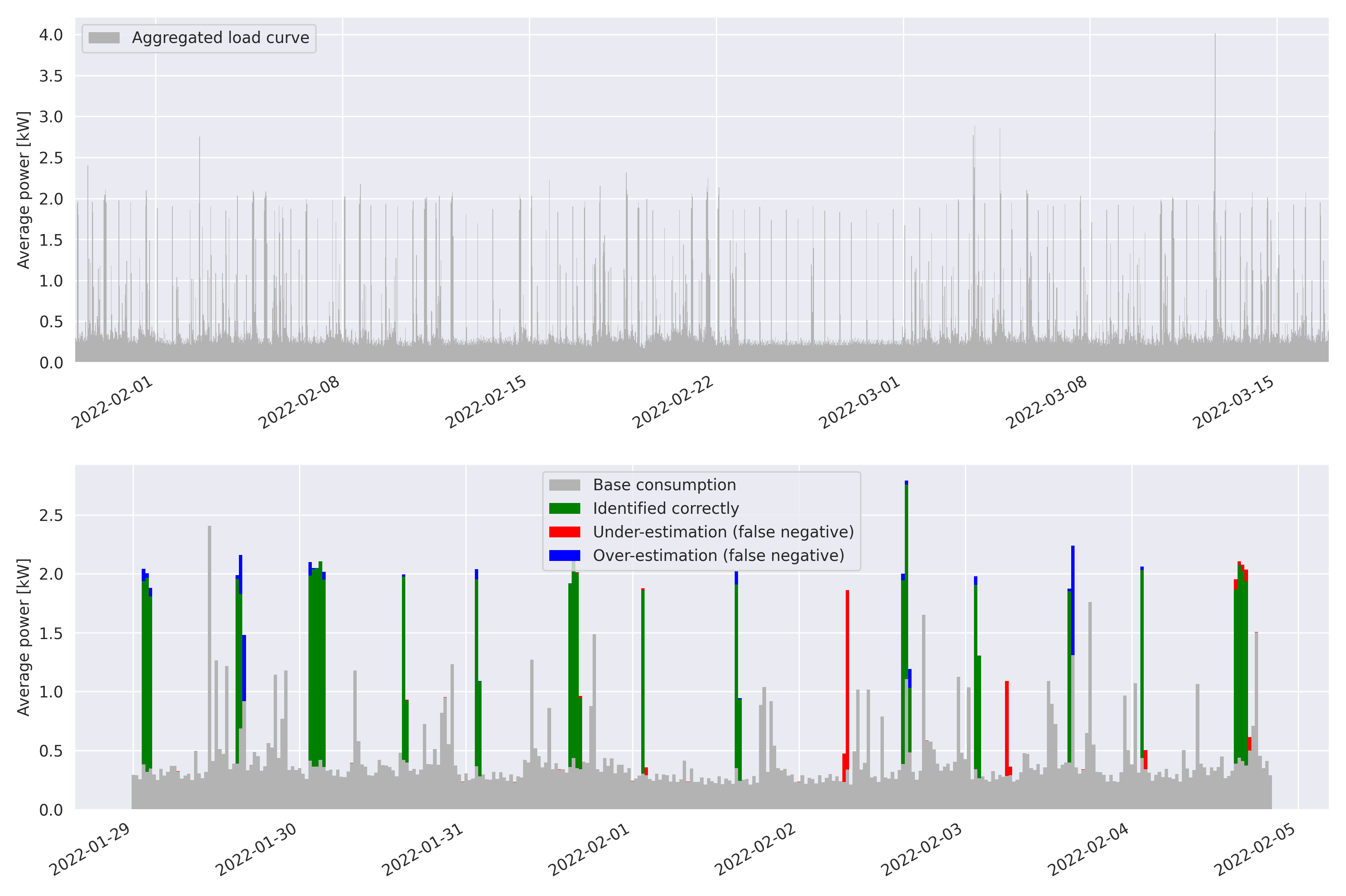
- Domain Knowledge Aids in Signal Disaggregation; the Example of the Cumulative Water HeaterIn this article we present an unsupervised low-frequency method aimed at detecting and disaggregating the power used by Cumulative Water Heaters (CWH) in residential homes. Our model circumvents the inherent difficulty of unsupervised signal disaggregation by using both the shape of a power spike and its temporal pattern to identify the contribution of CWH reliably. Indeed, many CHWs in France are configured to turn on automatically during off-peak hours only, and we are able to use this domain knowledge to aid peak identification despite the low sampling frequency. In order to test our model, we equipped a home with sensors to record the ground truth consumption of a water heater. We then apply the model to a larger dataset of energy consumption of Hello Watt users consisting of one month of consumption data for 5k homes at 30-minute resolution. In this dataset we successfully identified CWHs in 66.5% of cases where consumers declared using them. Inability of our model to identify CWHs in the consumption signal in the remaining cases is likely due to possible misconfiguration of CWHs, since triggering them during off-peak hours requires specific wiring in the electrical panel of the house. Our model, despite its simplicity, offers promising applications: detection of mis-configured CWHs on off-peak contracts and slow performance degradation.
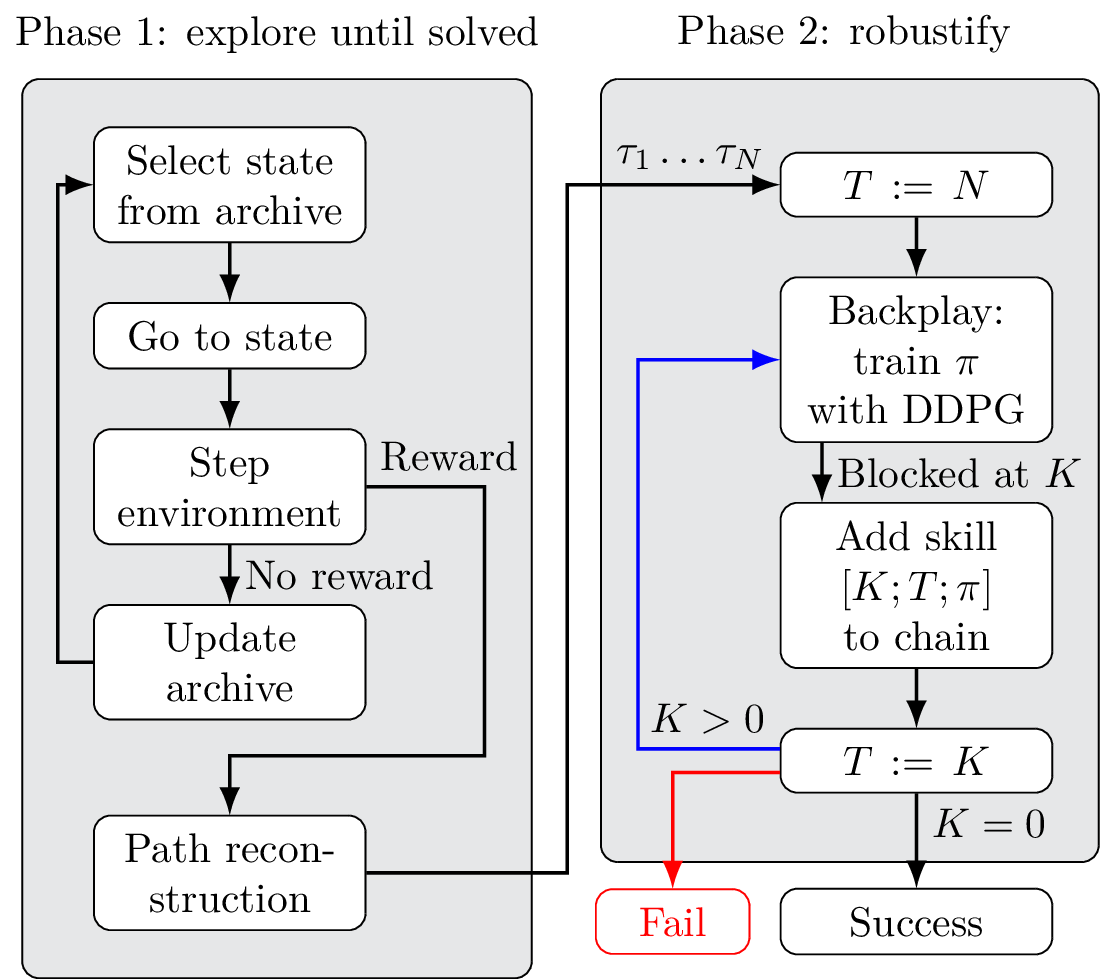
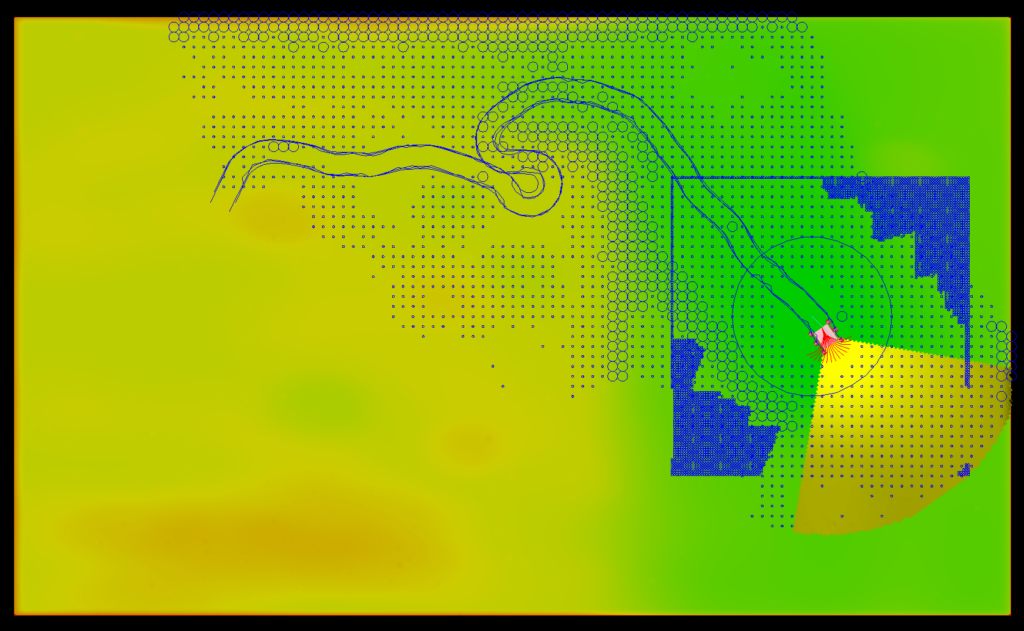
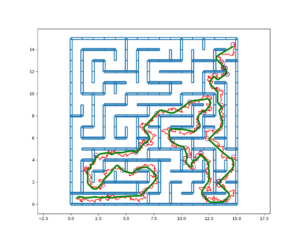
- PBCS: Efficient Exploration and Exploitation Using a Synergy between Reinforcement Learning and Motion PlanningThe exploration-exploitation trade-off is at the heart of reinforcement learning (RL). However, most continuous control benchmarks used in recent RL research only require local exploration. This led to the development of algorithms that have basic exploration capabilities, and behave poorly in benchmarks that require more versatile exploration. For instance, as demonstrated in our empirical study, state-of-the-art RL algorithms such as DDPG and TD3 are unable to steer a point mass in even small 2D mazes. In this paper, we propose a new algorithm called ”Plan, Backplay, Chain Skills” (PBCS) that combines motion planning and reinforcement learning to solve hard exploration environments. In a first phase, a motion planning algorithm is used to find a single good trajectory, then an RL algorithm is trained using a curriculum derived from the trajectory, by combining a variant of the Backplay algorithm and skill chaining. We show that this method outperforms state-of-the-art RL algorithms in 2D maze environments of various sizes, and is able to improve on the trajectory obtained by the motion planning phase.
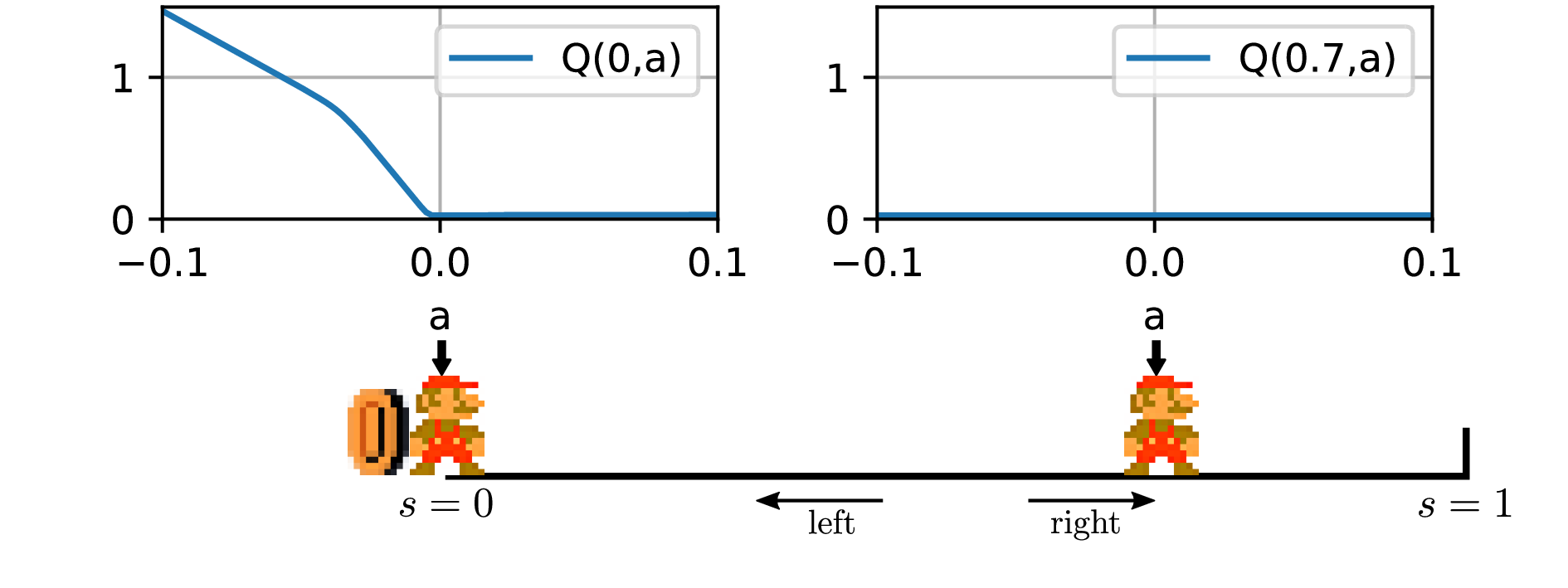
- The problem with DDPG: understanding failures in deterministic environments with sparse rewardsIn environments with continuous state and action spaces, state-of-the-art actor-critic reinforcement learning algorithms can solve very complex problems, yet can also fail in environments that seem trivial, but the reason for such failures is still poorly understood. In this paper, we contribute a formal explanation of these failures in the particular case of sparse reward and deterministic environments. First, using a very elementary control problem, we illustrate that the learning process can get stuck into a fixed point corresponding to a poor solution, especially when the reward is not found very early. Then, generalizing from the studied example, we provide a detailed analysis of the underlying mechanisms which results in a new understanding of one of the convergence regimes of these algorithms.