-
Comparer DPE et consommation a-t-il un sens ?
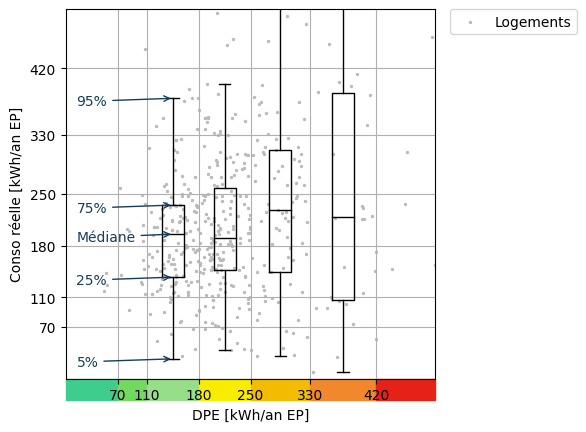
Récapitulatif des publications à ce sujet : Hello Watt a publié le 4 janvier une étude concluant à un manque de corrélation entre le DPE d’un logement, censé évaluer sa performance énergétique, et sa consommation d’énergie mesurée par les compteurs communicants. Pourquoi cette étude ? Dans sa mission de favoriser la transition énergétique des ménages,…
-
Predicting Home Energy Consumption, the Data-Driven Way
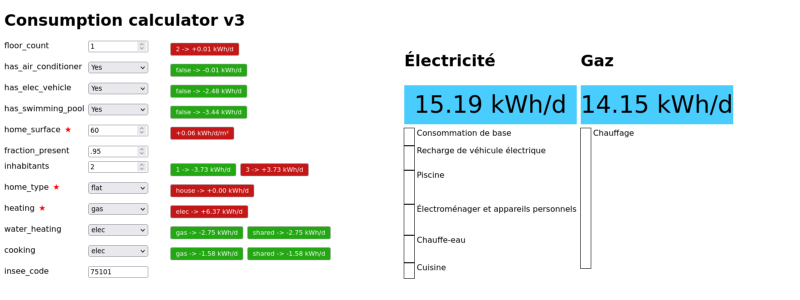
At Hello Watt, we help residential energy consumers reduce their energy bills through various means. This involves estimating their electricity and gas consumption based on information we collect either over the phone or through a form. We developed Consumption Calculator, a new model that works very similarly to the previous model except its coefficients are…
-
Domain Knowledge Aids in Signal Disaggregation; the Example of the Cumulative Water Heater
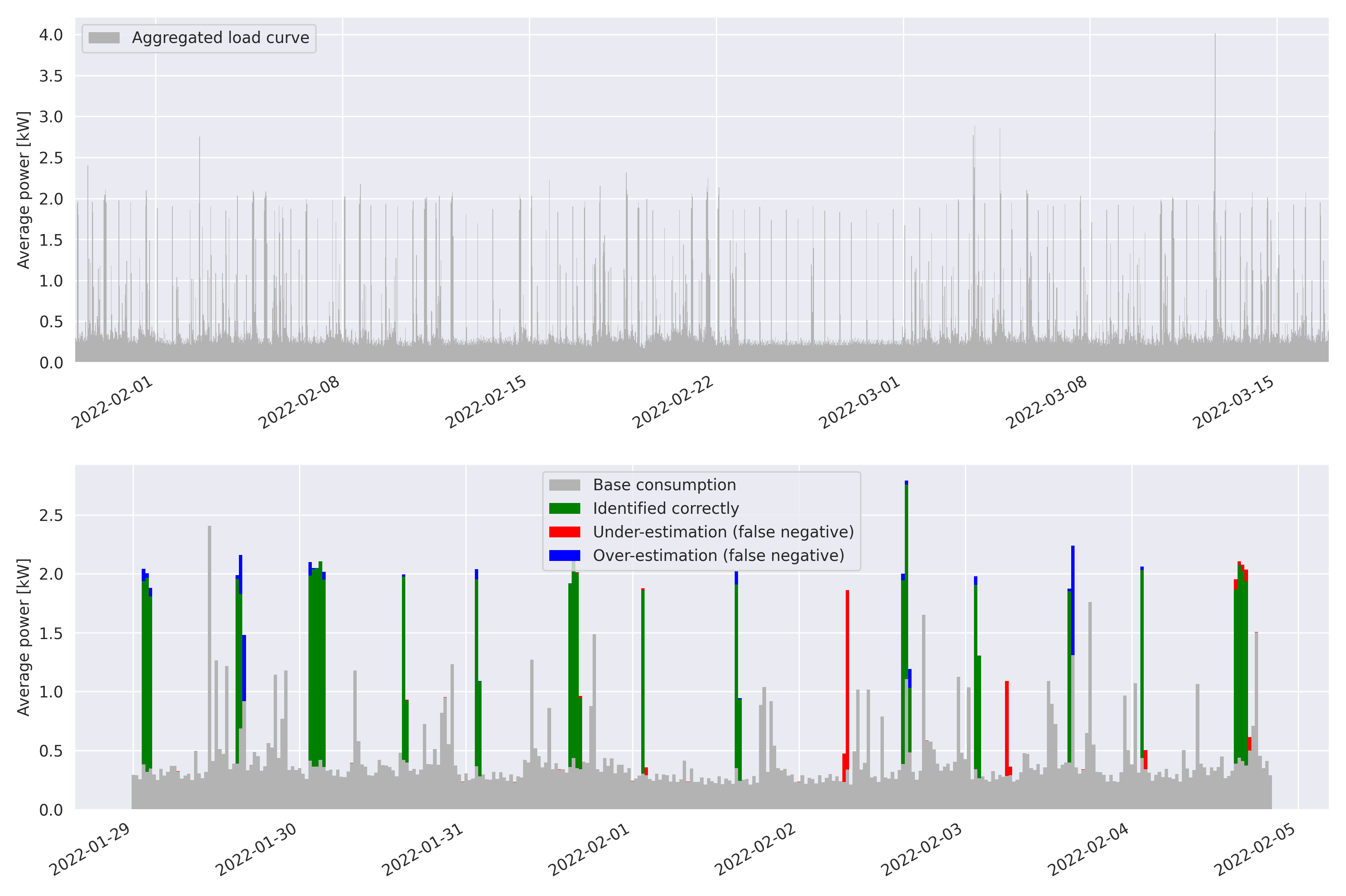
In this article we present an unsupervised low-frequency method aimed at detecting and disaggregating the power used by Cumulative Water Heaters (CWH) in residential homes. Our model circumvents the inherent difficulty of unsupervised signal disaggregation by using both the shape of a power spike and its temporal pattern to identify the contribution of CWH reliably.…
-
Optimization of Google Ads bidding taking into account our influence on the market
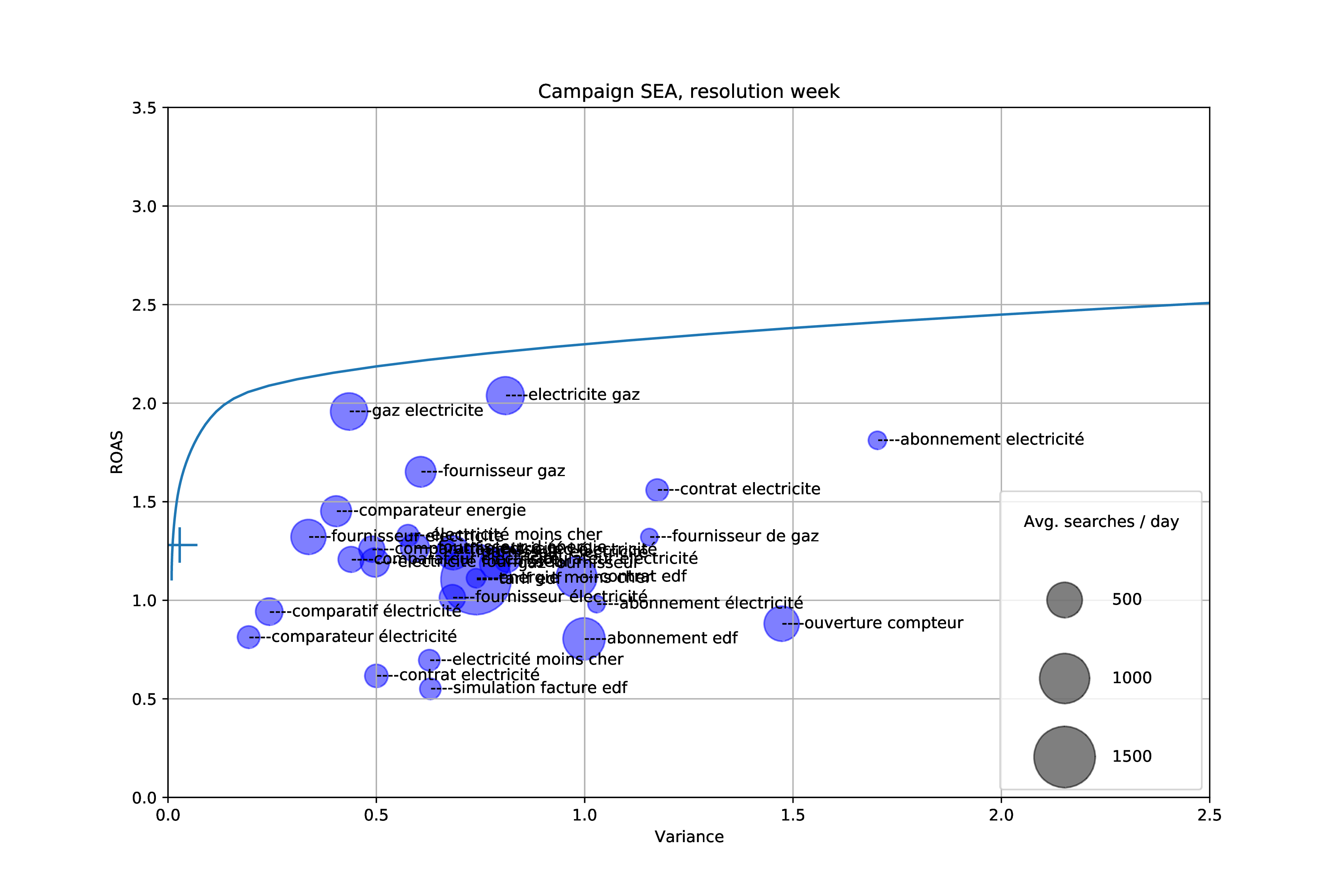
In this article, we give a brief overview of the Google Ads platform from the point of view of an advertiser as well as its available performance indicators and controls. We show how a simple portfolio optimization method indicates we can increase our ad returns significantly. Finally, we design a more complex model that takes…
-
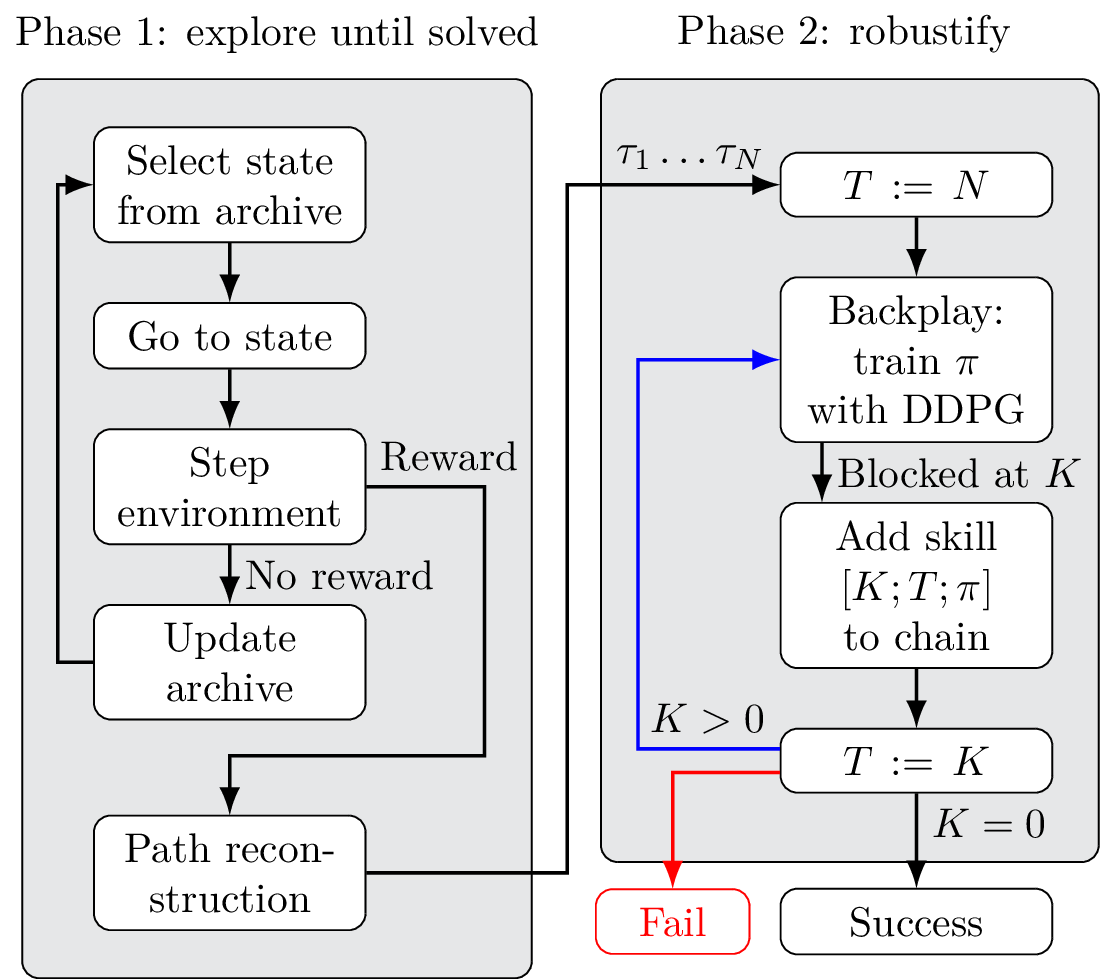
PBCS: Efficient Exploration and Exploitation Using a Synergy between Reinforcement Learning and Motion Planning
The exploration-exploitation trade-off is at the heart of reinforcement learning (RL). However, most continuous control benchmarks used in recent RL research only require local exploration. This led to the development of algorithms that have basic exploration capabilities, and behave poorly in benchmarks that require more versatile exploration. For instance, as demonstrated in our empirical study,…
-
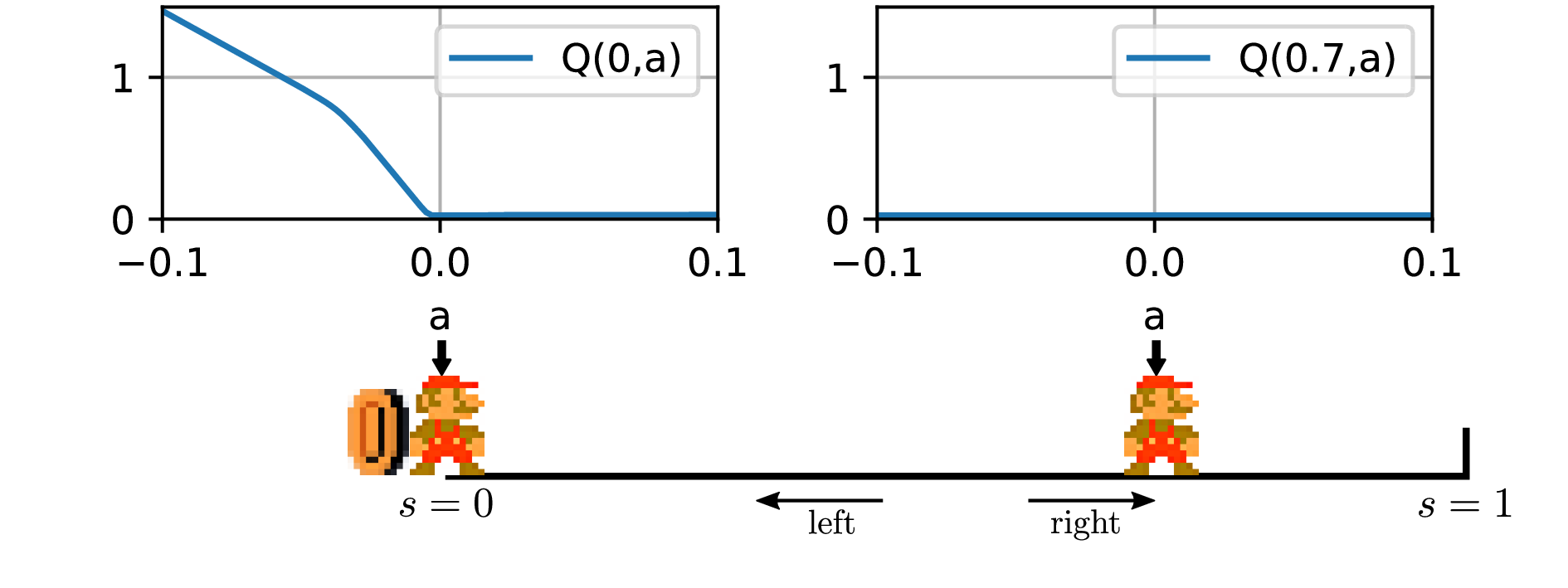
The problem with DDPG: understanding failures in deterministic environments with sparse rewards
In environments with continuous state and action spaces, state-of-the-art actor-critic reinforcement learning algorithms can solve very complex problems, yet can also fail in environments that seem trivial, but the reason for such failures is still poorly understood. In this paper, we contribute a formal explanation of these failures in the particular case of sparse reward…
-
Parking avec la voiture de Reeds et Shepp
Dans le cadre d’un projet de cours, nous (\, ^ et moi) avons construit un robot capable de se déplacer sur une surface plane en présence d’obstacles grâce aux courbes de Reeds et Shepp. Ces courbes sont en particulier utilisés pour la planification du mouvement lors du mode parking automatique sur certaines voitures (créneaux automatiques).…

-
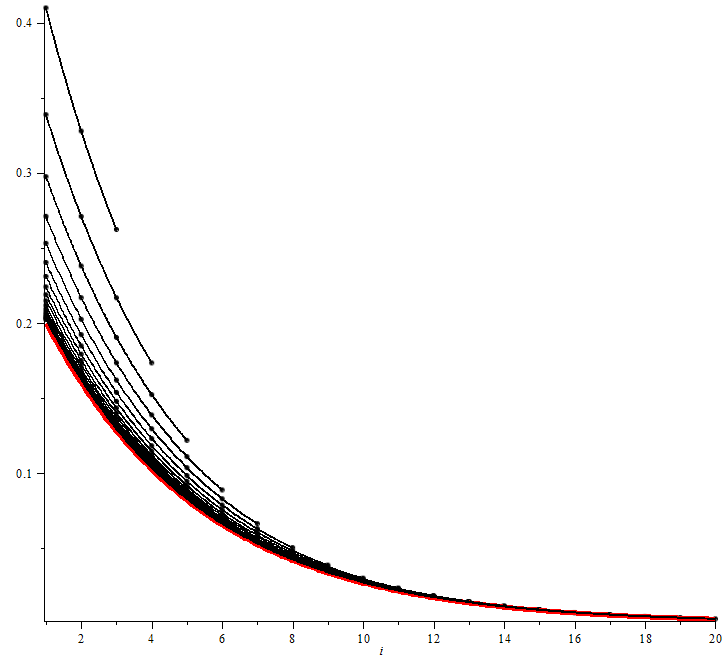
Chaînes de Markov et files d’attente
Les chaînes de Markov sont un outil mathématique permettant de modéliser l’évolution d’un système dont l’état au temps t+1 ne dépend que de son état au temps t, et possédant un nombre fini d’états. Ce document s’intéresse à l’étude de l’évolution des systèmes à partir de leur matrice de transition. En particulier, on énoncera une…
-
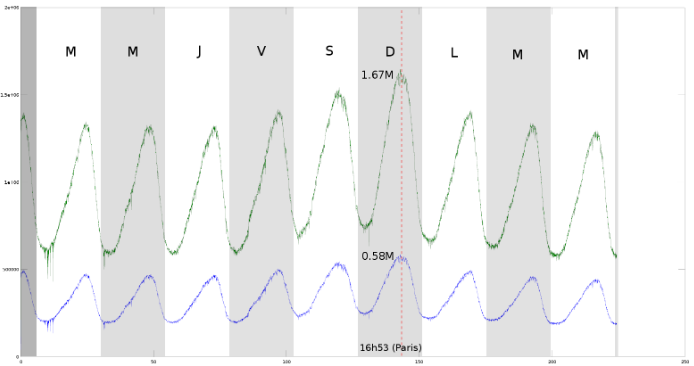
Parcours de la DHT BitTorrent
Le programme effectue un parcours de la DHT le plus exhaustif possible (environ un million de noeuds) en partant du bootstrap “router.bittorrent.com” de BitTorrent.Le réseau ainsi découvert est stocké au format csv pour pouvoir être ensuite étudié à l’aide d’outils tels que Octave ou Matlab.Comme la taille des données que le programme traite est conséquente,…
-
Surface reconstruction using Wasserstein metric
I did a two months summer internship in Inria’s TITANE team (Sophia-Antipolis, supervised by Pierre Alliez and David Cohen-Steiner) where I researched robust surface reconstruction from point samples using the Wasserstein distance (also known as earth-mover distance) as an error metric. Report Presentation

Guillaume Matheron
Data scientist, PhD in computer science